آموزش خوشه بندی در نرمافزار R
آموزش خوشه بندی در نرمافزار R به روش K-means
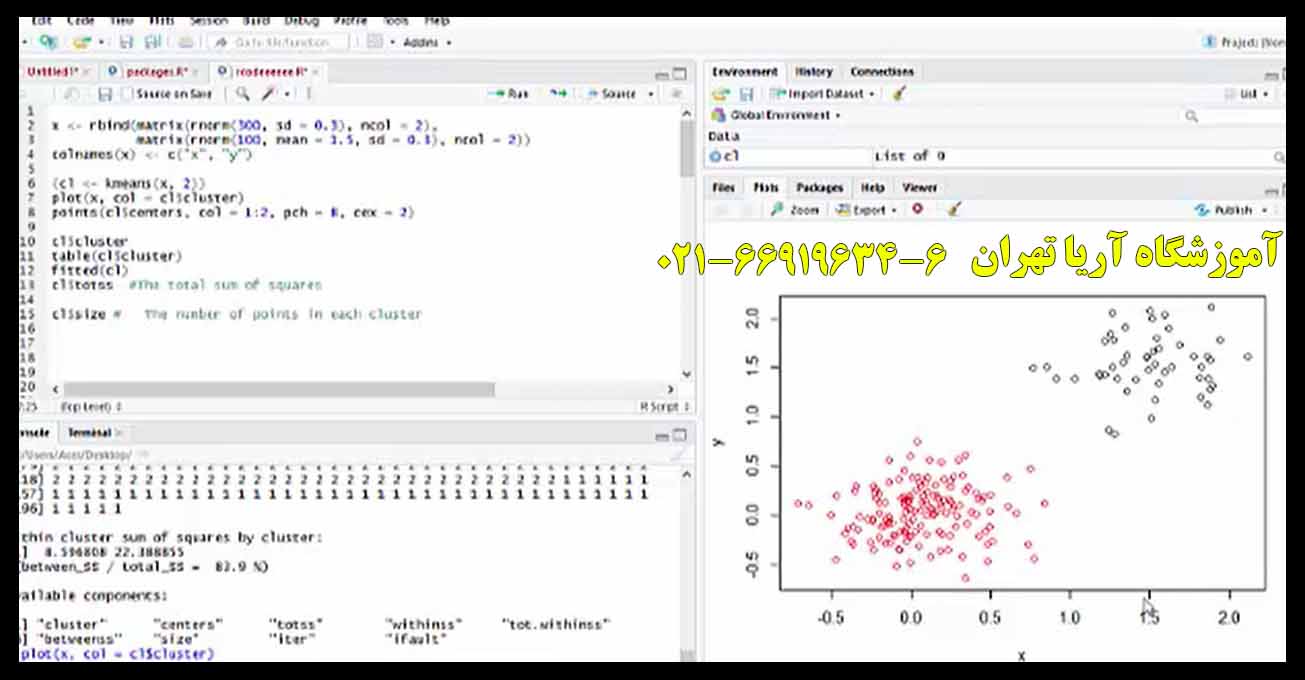
خوشهبندی K-means یکی از روشهای معتبر خوشهبندی است که بر اساس کمترین فاصلههای هر داده از مرکز یک خوشه (میانگین) خوشهبندی را انجام میدهد. برای دک بهتر مطلب در این مقاله سعی شده است آموزش خوشهبندی در نرمافزار R به کمک متون و فیلم آموزشی ارائه گردد. در نرمافزار R با استفاده از تابع Kmeans دادههای خود را خوشهبندی کرده و آنها را در k گروه بگنجانید به شکلی که مجموع مربعات فاصلهی دادهها از مراکز خوشهی خود حداقل باشد. درواقع این روش خوشهبندی از نقاط دادهها، باعث ایجاد مجموعههایی مجزا خواهد شد. بهطوریکه در هر مجموعه نقاط دادهها به مرکز خوشه نزدیکاند.
الگوریتم K-means در نرمافزار R
قبل از هر چیز باید بدانید که الگوریتم K-means دارای یک پارامتر K است، که نشاندهنده تعداد خوشههای مدنظر شما خواهد بود. الگوریتم K-means پایه بهصورت زیر تعریف خواهد شد
۱- این الگوریتم k مقدار را بهعنوان مراکز اولیه در نظر خواهد گرفت.
۲- میزان تکرار را مشخص میکند
۳- با تخصیص تمام نقاط به نزدیکترین مرکز K خوشه را تشکیل میدهد.
۴- سپس مراکز هر خوشه را دوباره محاسبه مینماید.
۵- این عملیات تا زمانی که مراکز تغییر نکنند انجام خواهد شد.
معمولاً مرکز خوشههای اولیه بهصورت تصادفی از میان نمونههای اولیه انتخاب میشوند. بنابراین خوشههای بهدستآمده در خوشهبندیها منحصربهفرد نیستند چراکه مرکز خوشههای اولیه در دو خوشهبندی مستقل K-means میتوانند متفاوت باشند. در الگوریتم K-means میتوان از معیارهای فاصلهی گوناگون بهره گرفت و خوبی یا بدی بهکارگیری آن معیار به نوع دادههایی که قرار است خوشهبندی گردند بستگی دارد.
آموزش دستور کلی خوشهبندی K-mean در زبان برنامهنویسی R بهصورت زیر است:
Kmeans (x, centers, iter.max=10, nstart=1, algorithm=c (“Hartigan-Wong”, “Lloyd” , “Forgy”, “MacQuenn”))
تعریف المانها در زبان برنامهنویسی R :
X : ماتریس عددی از دادهها؛ یا چیزی که میتواند جای یک ماتریس قرار بگیرد ( مثل: یک بردار عددی از دادهها یا یک دیتا فریم با ستونهای عددی )
Centers : تعداد خوشهها ( k ) یا مجموعهای از خوشههای اولیه را مشخص میکند. چنانچه یک عدد داشته باشیم یک مجموعهی تصادفی از سطرهای (مجزا) در X را بهعنوان مراکز اولیه در نظر میگیرد.
iter.max : حداکثر تعداد تکرار مجاز
nstart : اگر centers یک عدد باشد، nstart تعداد مجموعههای تصادفی که باید انتخاب شوند را نشان میدهد.
algorithm : Kmeans برای اجرا از الگوریتمهای متفاوتی استفاده میکند. این المان برای تابع kmeans الگوریتم خاصی را مشخص خواهد کرد. این تابع بهطور پیشفرض الگوریتم و ونگ را در خوشهبندی پیش میگیرد اما ممکن است بسیاری از نویسندگان روشهای دیگر K-means را ترجیح دهند. مثل الگوریتم مک کویین که اغلب به سایر الگوریتمها ترجیح داده میشود. اما بهطورکلی الگوریتم و ونگ نسبت به بقیه بهتر عمل میکند، بااینحال استفاده از یک شروع nstart>1 تصادفی معمولاً توصیه میشود. برای سهولت در برنامهریزی معمولاً K=1 مجاز است.
شما با شرکت در دوره آموزش نرمافزار و زبان برنامهنویسی R میتوانید تمام اصول آماری مربوط به این زبان را بهصورت حرفهای یاد بگیرید.
برای ثبتنام در دوره آموزش R با معتبرترین آموزشگاه مرکز تهران تماس بگیرید.
در فیلم آموزشی زیر طریقه خوشهبندی در نرم افزار R را بهطور عملی فرا خواهید گرفت.
فیلم آموزش خوشه بندی در نرمافزار R به روش K-means
آموزش زبان برنامه نویسی و نرمافزار آماری R در بهترین آموزشگاه مرکز تهران. آموزشگاه آریا تهران با برگزاری دوره های باکیفیت و کاربردی جهت کارآموزان متقاضی ورود به بازار کار و همچنین با اعطای مدرک فنی و حرفه ای و مدرک داخلی معتبر، یکی از معتبرترین آموزشگاه های مرکز تهران است.
برای ثبت نام در دوره آموزش نرم افزار و زبان برنامه نویسی R همین امروز اقدام کنید.
برای شرکت در دوره نرم افزار R روی لینک روبه رو کلید کنید – کلاس آموزش R
شما می توانید در دیگر دوره های حضوری زیر نیز در مجتمع فنی آریا تهران شرکت کنید.
آمورش icdl – آموزش زبان برنامه نویسی php – آموزش فتوشاپ – آموزش اتوکد در آموزشگاه اتوکد آریا تهران – آموزش حسابداری بازار کار نیز شرکت نمایید.








هنوز بررسیای ثبت نشده است.